Reducing traffic in Amazon Chime SDK app with Super Resolution
Note:
This article is also available here.(Japanese)
https://cloud.flect.co.jp/entry/2021/09/14/105249
Introduction
In my previous article, I introduced how to reduce the traffic by combining multiple users’ video streams into a single stream in a video conferencing system or game distribution system (Among us auto mute) using Amazon Chime SDK JS. In this article, I would like to introduce another way to reduce the traffic by reducing the resolution of the video image when it is sent, and use super-resolution technology after it is received.
The image below shows the result of applying this technique. The image on the far right is the result of using super-resolution. The left side of the red line has a higher resolution than the right side.

If the image is not clear enough, please download the video from the following link and check it out. download
Super Resolution and WebRTC
Super-resolution is a technology that outputs a high-resolution version of an input image. There are various definitions and methods, but here, please think of it as a technology that uses Deep Learning to increase the resolution of an image. Recently, NVIDIA provided a model and SDK optimized for TensorRT, which became a hot topic. In Japan, Softbank is working with NVIDIA on a demonstration experiment to apply TensorRT to video conferencing.

Purpose of this experiment
The idea this time is to use low-resolution images when sending data, and display them with higher resolution by super-resolution technology at each client that receives the data. Since low-resolution images are sent, the amount of data transfer (amount of data sent and received) can be expected to be reduced. In this article, I’d like to apply it to an application using Amazon Chime SDK JS to see if it works. NVIDIA’s SDK mentioned above does not seem to work in browsers, so I will implement the super-resolution part on my own.
Super Resolution: ESPCN
In addition to the above NVIDA model, there are many other proposals for super-resolution using Deep Learning. This time, the requirement is to be able to process in real time because it will be used for video conferencing. The ESPCN (efficient sub-pixel convolutional neural network) that we will use in this project is a super-resolution technique that has been proposed for use in real-time processing.

ESPCN was proposed by twitter in 2016. In the rapidly changing field of Deep Learning, it may be quite old now (2021), but as far as I know, there is no proposal for a lighter and faster model than ESCPN. (If you have something better, please comment!) It is also overwhelmingly fast in OpenCV’s Bencmark. ESPCN has also been used in ffmpeg as a super-resolution module.
For these reasons, we decided to implement super-resolution using ESPCN.
By the way, please refer to the paper for the details of this model, but the point that I personally found most interesting was the idea of treating the image as a YCbCr color space and adding super-resolution processing only to the luminance signal. (This idea itself was proposed in another paper.) Since the human eye is most sensitive to luminance signals, it is possible to achieve a certain level of high-quality super-resolution simply by increasing the resolution of luminance signals. As mentioned in the title, the main points of this model are the sub-pixel convolution layer and pixel shuffle (depth_to_space), but please read the paper for more details.
Demo of ESPCN
In this experiment, we created and trained an ESPCN model in Tensorflow. The figures below show 480x500 image which is made from 240x250 image. The figure on the left is the high-resolution version using ESPCN. The image on the right was enlarged using HTMLCanvasElement’s drawImage. (Image have not yet been transferred via WebRTC.) You can see that the left image clearly shows the outline and wrinkles of the clothes. If the image on the blog is not clear enough for you, you can try the demo page. The demos used here are stored in this repository.

The figure below shows the processing time when both width and height are doubled to a higher resolution. The horizontal axis is the width of the input image. The vertical axis is the processing time (msec). The processing time is measured in three different environments. The blue one is the one run by TensorflowJS on a PC with RTX1660. The red one is TensorflowLite (Wasm/SIMD version) running on an M1 MacBook Air, which is used because it runs faster than TensorflowJS. The black image shows a ThinkPad (corei5 8350U 1.7GH) running the Wasm/SIMD version of TensorflowLite. TensorflowLite was also faster than TensorflowJS here.
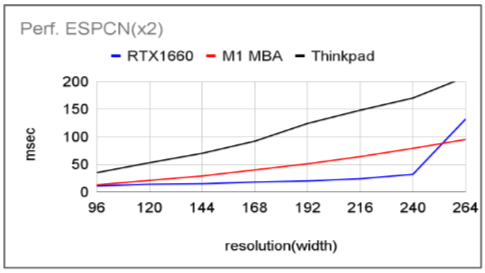
The Thinkpad is a very old PC, so looking at only PCs with RTX1660 and MBAs, it seems to run within 100msec (= 10fps or more) if the width is around 240px. Therefore, we will proceed with the verification based on the assumption that data with a width of 240px will be used.
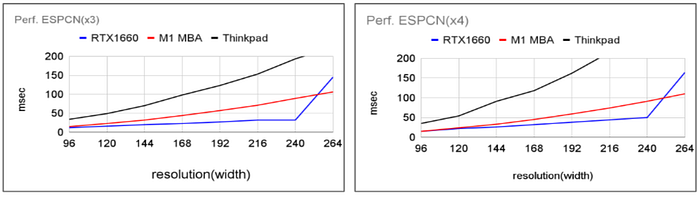
We also measured the processing time when the width and height were increased by a factor of 3 and 4, and the trend was the same. The data can be found in the appendix.
Experiment
Now, I would like to verify the following two points with a system that uses low-resolution images sent by WebRTC and high-resolution images at the receiving end.
- How much less data can be transferred?
- How close to the original image can it be restored using super-resolution?
Structure of the experiment
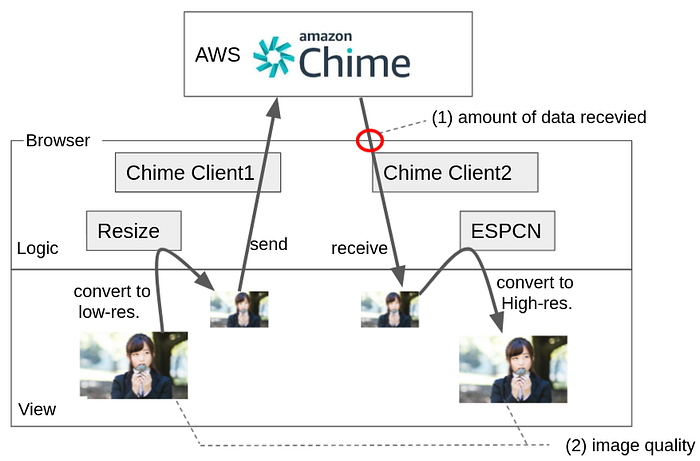
The above figure shows the configuration of this experiment. Two Chime Clients are running simultaneously in a single browser. One of them sends the video after reducing the resolution, and the other receives it. After receiving the video, ESPCN is used to increase the resolution. In this configuration, (1) check the amount of the data to be received. And (2) we check the quality of the original video to see how well it is restored by the high-resolution conversion.
Result
(1) The amount of data transfered
When the video is transmitted at the original size, the amount of data on both the sending and receiving sides is 300–400KiB/Sec, but if the video is transmitted at 1/2 resolution, the amount can be reduced to 100–150KiB/Sec at once.
(2) Quality
The following video shows a 480x360 image transferred at low resolution to a 240x180 image, and then again at high resolution to 480x360. The left side of the red line is the ESPCN high-resolution version. The right side of the red line was resized with HTMLCanvasElement’s drawImage.
I think the ESPCN is much clearer. If you have trouble understanding it from the youtube video, try downloading the video from the link below.
The graph below shows the results of similarity testing using PSMR and SSIM with still images. The still images used are test data from the DIV2K dataset (100 images).
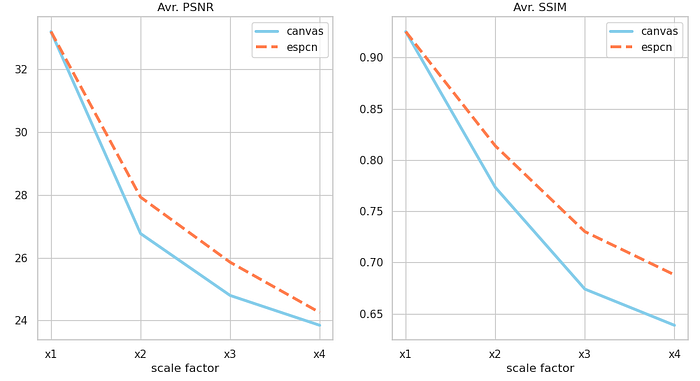
As we found out during the experiment, the received video seems to be slightly different each time due to the network conditions, etc., and the PSNR and SSIM values changed each time we evaluated. Therefore, it may be better to consider these values as reference values to see the general trend. I will store the above video or the code of this experiment in the repository described below, so you can see it for yourself. In any case, using ESPCN is much closer to the original image than using HTMLCanvasElement’s drawImage to enlarge it. On the other hand, even when the resolution is increased to double the width and height, the level is not indistinguishable from the original image.
Discussion
This time, we were able to reduce the amount of data transfer significantly (less than half) by reducing the width and height of the original 480x360 resolution video by 1/2. However, even when the resolution was reduced to 1/3 or 1/4 of the height and width, the rate of data transfer reduction gradually slowed down. Therefore, to a certain extent, it is possible to reduce the resolution in order to reduce the amount of data transfer.
On the other hand, with PSNR and SSIM, it’s hard to understand intuitively, so it’s better to watch the demo. I think you’ll see a significant difference in the degradation of the video when the width and height are reduced to 1/2, 1/3, and 1/4.
It is difficult to determine how much video degradation is acceptable, as it depends on the use case and individual senses. It is also a tradeoff between the amount of data transfer. Personally, I think that sending and receiving data at half the resolution of the original image is acceptable in many cases, because the human eye does not notice any significant degradation in the image. In addition to this, the higher resolution using ESPCN will reduce the degradation of the video, which will increase the number of applicable cases.
Summary
In this experiment, I tried to see if it would be possible to reduce the amount of data transmission by sending video images at a reduced resolution and then using super-resolution technology after receiving them. As a result of the experiment, I think I was able to confirm that the video can be restored better than simply using HTMLCanvasElement’s drawImage to restore (resize) the resolution (probably subjective).
Since image quality degradation is unavoidable, it is difficult to say in which case we can use it. However, we believe that using super-resolution (ESPCN) will make it easier to choose the option of transmitting at a reduced resolution in environments where bandwidth is limited.
In addition, although I didn’t mention it this time, the current upper limit of resolution that Amazon Chime SDK JS can handle is 1280x720, so I think it can be applied to cases where you want to use a resolution that exceeds this on the client side.(this may require hardware of considerable performance.)

Repository
The code used in this experiment is stored in this repository.
Appendix
Processing time for high resolution with ESPCN (x3 and x4)
Acknowledgements
I used images of people, videos of people, and background images from these sites.
Disclaimer
Recording or capturing Amazon Chime SDK meetings with the demo in this blog may be subject to laws or regulations regarding the recording of electronic communications. It is your and your end users’ responsibility to comply with all applicable laws regarding the recordings, including properly notifying all participants in a recorded session, or communication that the session or communication is being recorded, and obtain their consent.
